웹 크롤링은 데이터를 수집하고 분석하는 데 있어 필수적인 기술입니다.
특히, Python은 웹 크롤링을 위한 강력한 언어로 널리 사용되고 있습니다. 이 글에서는 Python을 사용하여 웹 크롤링을 수행하기 위한 HTML 구조의 중요성과 이를 효과적으로 다루는 방법을 상세히 살펴보겠습니다.
HTML의 기본 구조
HTML(HyperText Markup Language)은 웹페이지를 구성하는 가장 기본적인 요소입니다. 웹 크롤링을 위해서는 먼저 HTML의 구조를 이해하는 것이 중요합니다.
태그(Tag)
HTML은 다양한 태그들로 구성되어 있으며, 각 태그는 웹페이지의 다른 부분을 나타냅니다.
예를 들어 '<p>' 태그는 문단을, '<a>'태그는 하이퍼링크를 나타냅니다. 각 태그는 '<태그명>'으로 시작하여 '</태그명>'으로 종료됩니다.
속성(Attribute)
요소(Element)
HTML 요소는 시작 태그, 속성, 태그 사이의 내용, 종료 태그로 구성됩니다.
예를 들어, '<p>Hello World</p>'는 'Hello World'라는 텍스트를 포함하는 '<p>'태그의 요소입니다.
Python과 웹 크롤링
Python으로 웹 크롤링을 하기 위해서는 HTML을 파싱하고 요소를 추출하는 라이브러리가 필요합니다. 가장 대표적인 라이브러리는 BeautifulSoup과 Selenium입니다.
BeautifulSoup을 활용한 웹 크롤링
BeautifulSoup 설치

BeautifulSoup 사용 예시

BeautifulSoup은 HTML 문서를 파싱하여 Python 객체로 만들어주며, 이를 통해 쉽게 데이터를 추출할 수 있습니다.
Selenium을 활용한 웹 크롤링
동적 웹페이지의 경우, JavaScript가 데이터를 로드하는 경우가 많습니다. 이럴 때는 Selenium을 사용하여 실제 브라우저 환경에서 웹페이지를 조작하고 데이터를 크롤링할 수 있습니다.
Selenium 설치

Selenium 사용예시
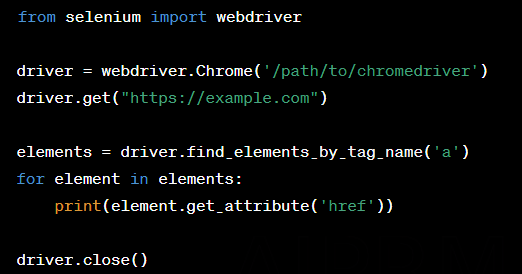
Selenium은 웹페이지의 동적인 부분까지 포착하여 크롤링이 가능합니다.
HTML 구조 깊이 파악하기
웹 크롤링의 성공은 웹페이지의 HTML 구조를 얼마나 잘 이해하고 파악하는가에 달려 있습니다. 복잡한 웹페이지의 경우, 다음과 같은 방법으로 HTML 구조를 깊이 파악할 수 있습니다.
1. 개발자 도구 사용:
브라우저의 개발자 도구를 사용하여 웹페이지의 HTML 구조를 직접 살펴볼 수 있습니다.
2. 중첩된 태그 이해:
대부분의 웹페이지는 중첩된 태그 구조를 가지고 있습니다. 이 구조를 이해하는 것이 중요합니다.
3. 동적인 요소 인식:
JavaScript에 의해 동적으로 변하는 요소들을 인식하고, 이를 Selenium 등을 통해 적절히 처리해야 합니다.
4. 유효한 데이터 식별:
웹페이지에서 유효한 데이터와 불필요한 데이터를 구분하는 능력을 기르는 것이 중요합니다.
고급 HTML 구조 분석 전략
웹 크롤링의 효율성을 극대화하기 위해서는 고급 HTML 구조 분석 전략이 필요합니다. 이를 위해 다음과 같은 접근 방법을 고려할 수 있습니다.
중요 HTML 요소
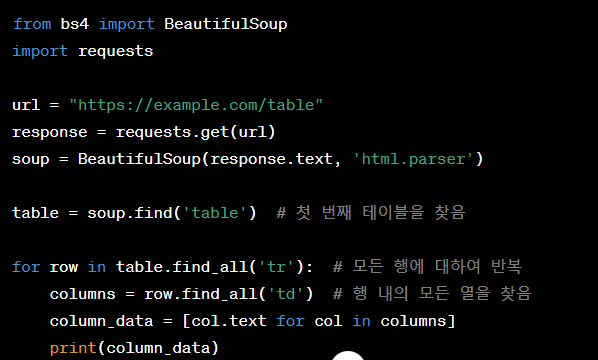
테이블(Table):
데이터가 테이블 형태로 구성되어 있는 경우, '<table>', '<tr>', '<td>' 태그를 주의 깊게 살펴봅니다.

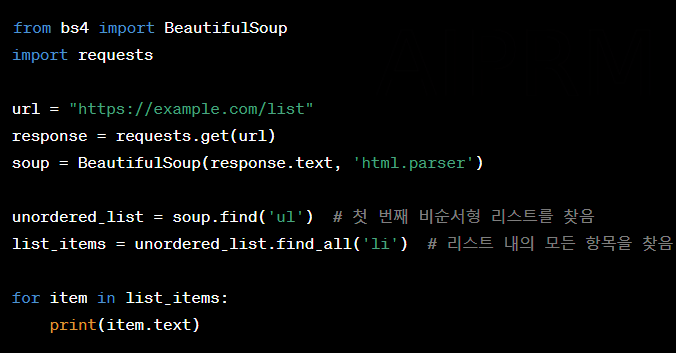
리스트(List):
목록 형태의 데이터는 '<ul>', '<ol>', '<li>' 태그를 통해 구성됩니다.

폼(Form):
사용자 입력이 필요한 경우 '<form>', '<input>', '<button>' 등의 태그가 사용됩니다.


CSS 선택자 활용
CSS 선택자는 특정 HTML 요소를 빠르고 정확하게 선택하는 데 유용합니다. BeautifulSoup과 Selenium 모두 CSS 선택자를 지원하므로, 이를 활용해 효율적으로 데이터를 추출할 수 있습니다.
JavaScript 생성 요소 이해
동적 웹사이트에서는 JavaScript가 HTML 요소를 생성하거나 변경합니다. 이런 경우, 웹페이지가 완전히 로드된 후에 필요한 데이터에 접근해야 합니다. Selenium을 사용하면 JavaScript가 실행된 후의 웹페이지 상태를 크롤링할 수 있습니다.
마무리
웹 크롤링은 매우 강력한 도구이지만, 이를 효과적으로 사용하기 위해서는 웹의 기본적인 구조인 HTML에 대한 깊은 이해가 필요합니다. Python과 함께 BeautifulSoup과 Selenium 같은 라이브러리를 사용하면 복잡한 웹사이트의 데이터도 쉽게 추출할 수 있습니다.
'Python, R, Excel 등등' 카테고리의 다른 글
| 책 리뷰: "공공기관/공무원 재직자를 위한 Python으로 시작하는 업무자동화" (0) | 2023.11.20 |
|---|---|
| Selenium으로 웹 크롤링 시뮬레이션하기(카드고릴라 1~100위 크롤링) (0) | 2023.11.01 |
| Python을 사용하여 Windows 환경에서 컴퓨터를 자동으로 켜고 끄는 방법과 Pyautogui로 생성한 파일을 매일 자동으로 실행하는 방법(예제 코드 포함) (0) | 2023.07.20 |
| Python으로 시계열 데이터를 예측하는 방법에 대한 튜토리얼 및 예제 (0) | 2023.06.04 |
| R 초급자를 위한 튜토리얼 (0) | 2023.06.02 |



